How To Implement Web Scraping Using Beautifulsoup And Python?
- - Category: Programming
- - 05 Aug, 2021
- - Views: 821
- Save
Python and BeautifulSoup can be very helpful in doing web scraping. This blog tells you How to Implement Web Scraping.

Mainly, there are two ways of scraping data from websites:
Using a Website API: (if it already exists). For instance, Facebook has its Facebook Graph API that permits retrieval of posted data on Facebook.
Access HTML of a webpage as well as scrape useful data from that. The method is known as web data extraction or web harvesting or web scraping.
This blog discusses about the steps associated in data scraping using implementation of Python’s Web Scraping framework named BeautifulSoup.
Steps Associated in Web Scraping:
- Send the HTTP request into the webpage URL you wish to access. A server reacts to a request through returning a webpage’s HTML content. For that task, we would utilize a third-party HTTP library to treat Python-requests.
- When we get the access of HTML content, our job will be to parse the data. As most HTML data gets nested, we just cannot scrape data using string processing. We need a parser that can make a tree structure of HTML data. Many HTML parser libraries are available however, the most superior one is HTML5lib.
- Now, we require to navigate and search the parse tree, which we have made, i.e. tree traversal. For that task, we will use other third-party Python library called Beautiful Soup. This is a Python library to pull data out from XML and HTML files.
Step 1: Installation of the Necessary Third-Party Libraries
The easiest way of installing external libraries in Python is using pip. Pip is the package management system utilized for installing and managing software packages prepared in Python.
You just need to this:
pip install requestspip install html5libpip install bs4
Step 2: Access HTML Content from a Webpage
import requestsURL = "https://www.geeksforgeeks.org/data-structures/"r = requests.get(URL)print(r.content)
It’s time to know the piece of code.
- Initially, import a requests library.
- After that, identify the webpage URL you need to extract.
- Send the HTTP request to any specified URL as well as save response from the server in the response object named r.
- Now, having print r.content for getting raw webpage HTML content. This is of the ‘string’ type.
Step 3: Parse the HTML Webpage content
#This will not run on online IDEimport requestsfrom bs4 import BeautifulSoup URL = "http://www.values.com/inspirational-quotes"r = requests.get(URL) soup = BeautifulSoup(r.content, 'html5lib') # If this line causes an error, run 'pip install html5lib' or install html5libprint(soup.prettify())
A good thing about a BeautifulSoup library is, it is created on top of an HTML parsing library like html.parser, lxml, html5lib, etc. Therefore, BeautifulSoup object as well as identify the parser library could be made at the similar time.
In the given example,
soup = BeautifulSoup(r.content, 'html5lib')
We have created a BeautifulSoup object through passing two different arguments:
r.content : This is a raw HTML content.
html5lib : Identifying an HTML parser that we wish to utilize.
Now, as soup.prettify() is produced, it provides a visual representation about the parse tree made from raw HTML content.
Step 4: Search and Navigate Using a Parse Tree
Now, we want to scrape a few helpful data from HTML content. A soup object has data in nested structure that might be programmatically scraped. In this example, we scape a webpage having some quotes. Therefore, we would love to make a program for saving those quotes (as well as all the relevant data about them).
#Python program to scrape website #and save quotes from websiteimport requestsfrom bs4 import BeautifulSoupimport csv URL = "http://www.values.com/inspirational-quotes"r = requests.get(URL) soup = BeautifulSoup(r.content, 'html5lib') quotes=[] # a list to store quotes table = soup.find('div', attrs = {'id':'all_quotes'}) for row in table.findAll('div', attrs = {'class':'col-6 col-lg-3 text-center margin-30px-bottom sm-margin-30px-top'}): quote = {} quote['theme'] = row.h5.text quote['url'] = row.a['href'] quote['img'] = row.img['src'] quote['lines'] = row.img['alt'].split(" #")[0] quote['author'] = row.img['alt'].split(" #")[1] quotes.append(quote) filename = 'inspirational_quotes.csv'with open(filename, 'w', newline='') as f: w = csv.DictWriter(f,['theme','url','img','lines','author']) w.writeheader() for quote in quotes: w.writerow(quote)Before we move on, we suggest you to experience a webpage’s HTML content that we have printed through soup.prettify() technique as well as try and find the pattern or ways of navigating the quotes.
You can see that all quotes are within the div container whose id include ‘all_quotes’. Therefore, we get that div component (known as table in given code) through find() technique :
table = soup.find('div', attrs = {'id':'all_quotes'}) The initial argument is an HTML tag that you wish to search as well as second argument is the dictionary kind element for specifying extra attributes related with the tag. find() technique returns the initial matching elementa. You may try and print table.prettify() for getting the sense about what the code does.
Nowadays, in these table elements, one could notice that every quote is within the div container and class is quoted. Therefore, we repeat through every div container where the class is quoted.
Now, we utilize findAll() technique which is like finding method for arguments however, it returns the list of different matching elements. Every quote is iterated using the variable named row.
Here, the example is given of row HTML content to give better understanding:
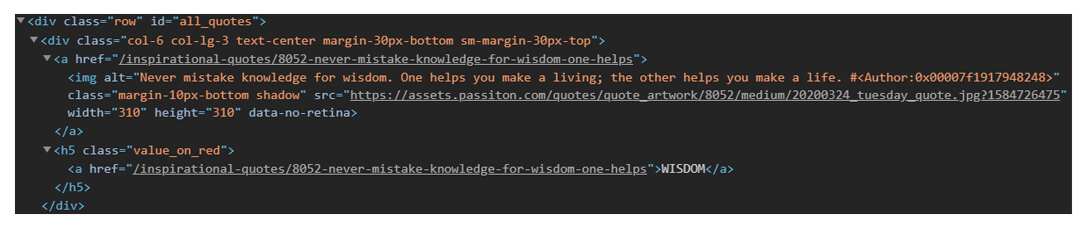
Now, think about the code given here:
for row in table.find_all_next('div', attrs = {'class': 'col-6 col-lg-3 text-center margin-30px-bottom sm-margin-30px-top'}): quote = {} quote['theme'] = row.h5.text quote['url'] = row.a['href'] quote['img'] = row.img['src'] quote['lines'] = row.img['alt'].split(" #")[0] quote['author'] = row.img['alt'].split(" #")[1] quotes.append(quote)We made a dictionary for saving all data about the quote. Its nested structure could be used with dot notation. For using the text within the HTML element, we have used .text :
quote['theme'] = row.h5.text
We could add, modify, access, or remove a tag’s features. It is done through treating a tag like a dictionary:
quote['url'] = row.a['href']
Finally, all quotes are added in the list named quotes.
In conclusion, we would love to save all the data in the CSV file.
filename = 'inspirational_quotes.csv'with open(filename, 'w', newline='') as f: w = csv.DictWriter(f,['theme','url','img','lines','author']) w.writeheader() for quote in quotes: w.writerow(quote)
We have created a CSV file named inspirational_quotes.csv as well as save all quotes in that for further use.
Therefore, it was an easy example about how to make a web scraper using Python. From there, you could try and scrap other websites of your selection. For all the queries, you can use the comments section.